Predicting Use of Contraception in Asia with Machine Learning Algorithms
Project report of building classification models with MICS microdata using caret in R
This post focuses on the overall predictive modelling workflow, including analysis strategy, model comparison, and limitations. If you are more interested in the technical aspect or viewing the code, please see:
The repository is available on GitHub.
1. Introduction
Contraception is designed to prevent pregnancy. By preventing unintended pregnancy, contraceptive methods help women to avoid pregnancy- and birth-related morbidity and mortality. Ensuring access to contraception advances human rights, including the right to life and liberty, freedom of opinion and expression, and the right to work and education.¹ In 2019, among the 1.9 billion women of reproductive age (WRA) living around the world,² 190 million women had an unmet need for family planning for various reasons, such as health concerns, lack of access, or opposition from others.³
The study aims to build classification models with machine-learning (ML) techniques to predict the use of contraception in Thailand, Mongolia, and Laos. Specifically, the goal is to identify WRA not using contraception. ML can often be more efficient in establishing a relationship between multiple features⁴ and may be able to recognise patterns in characteristics associated with not using contraception. While not all have an unmet need for family planning, being able to classify these individuals can provide a basis to expand access to contraception.
2. Method
2.1. Data Source and Processing
The study uses data from the 6th Multiple Indicator Cluster Surveys (MICS), which are household surveys implemented by countries with the assistance from the United Nations Children’s Fund (UNICEF) to provide internationally comparable, statistically rigorous data on the situation of children and women. Data on the use of contraception are included in the women of reproductive age (15–49 years) module. The files published by the UNICEF are country-specific; therefore, the dataset for the analysis was created manually.
For features, in addition to the outcome, currently using a method to avoid pregnancy, a variable must be available in three datasets, comparable across nations, and have at least 95% response rate to be included. Eight variables meeting the criteria were selected as predictors: age; highest educational attainment; country-specific wealth percentile; marital status; country; residence (urban or rural); indicators for ever given birth and ever had child or children who later died. Values for the highest education attainment were re-coded[1] to standardise the responses. For instances, observations with “No Response,” “Don’t know,” “NA,” or missing data in any variable were excluded to ensure the quality of the data. Overall, the dataset has 58,356 cases.
2.2 Analysis Strategy
Five ML models were used to predict the use of contraception:
• K-nearest neighbour (KNN)
• Decision tree
• Random forest
• Logistic regression with Bayesian classifier
• Generalised additive model (GAM).
KNN and tree-based models are non-parametric methods that do not make explicit assumptions about the relationships among variables. Since most variables are qualitative, these models provide higher flexibility and potentially better predictive performance. On the other hand, logistic regression and GAM are non-linear functions that estimate the probability for observation to belong in a particular category and are selected to take advantage of the numerical variable, age. The Bayesian classifier then classifies a case to the category with the largest probability.
The dataset was split into training (85%) and validation (15%) according to the distribution of the target variable. Predictive models were developed with the training set and evaluated with 10-fold cross-validation to identify the best forms or parameters with the lowest error rate for each model. Once every model was optimised, the validation set was used to test the performance on the accuracy, sensitivity, specificity, positive prediction value (PPV), and negative prediction value (NPV).
3. Discussion
3.1. Descriptive Summary of Background Characteristics
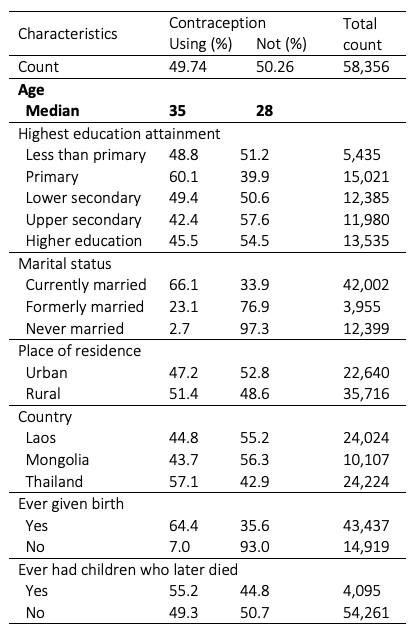
Table 1 shows that out of 58,356 samples, 49.74% use contraception, and 50.26% do not. The median age is 35 and 28, respectively. There are considerable differences in contraceptive use by marital status and by experience giving birth. Only 2.7% and 23.1% of never and formerly married women use contraception, while 66.1% currently married individuals does. Women who have never given birth have a significantly lower prevalence of contraceptive use (7%) than those with experience giving birth (64.4%).
3.2. Model Training
Three models have parameters: k, the number of neighbours, for KNN; maxdepth, maximum depth of any node of the final tree, for decision tree; mtry, the number of variables tried at each split, for random forest. They were provided with a set of parameter and evaluated with ten-fold cross-validation. For logistic regression and GAM, models without parameter, various formulas or predictor specifications were given to cross-validate.
3.2.1. KNN
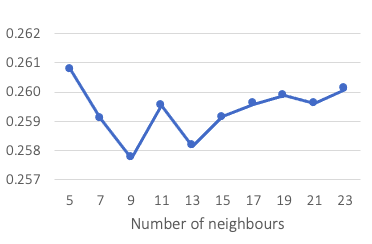
A list of integer, from 5 to 23 with an interval of two, was provided for k. The result indicates that the model using nine neighbours (k = 9) has the lowest 10-fold cross-validation error rate of 25.78 per cent, as shown in Figure 1.
3.2.2. Decision tree
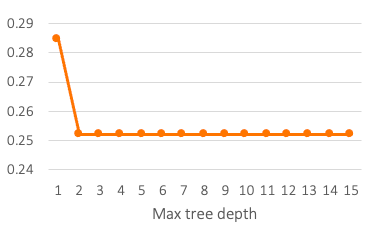
Cross-validation results for ten maxdepth parameters are provided in Figure 2. After two, increasing tree depth does not yield improvements in error rate. The best tree (maxdepth = 2) has two splits, one for the indicator for ever given birth and one for marital status.
According to the model, women who have never given birth are predicted to be not using contraception. For people who had experience giving birth, if they were formerly married or in a union, the outcome is not using contraception. If they were currently or never married, the model predicted them to be using methods to avoid pregnancy. The cross-validation error rate is 25.21 per cent.
3.2.3. Random forest and bagging
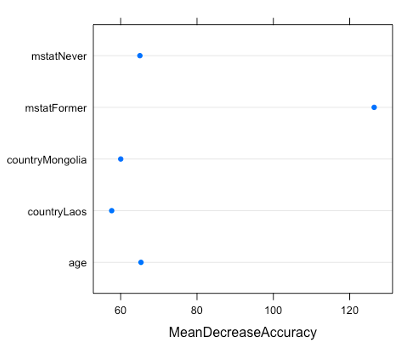
The mtry parameter is nine for bagging and three for random forest.[2] Both models have 500 trees. The 10-fold cross-validation error rate is 25.60% for bagging and 23.33% for random forest; therefore, random forest with mtry of three is selected. Figure 3 presents the importance measures, the mean decrease in accuracy, for the five most important variables.
The mstatFormer and mstatNever refer to formerly married and never married categories in the marital status (mstat) feature.
3.2.4. Logistic regression with Bayesian classifier
Two sets of three formulas were given. The first one included age, education attainment, marital status, the indicator for ever given birth, and interaction between country and country-specific wealth percentile. The other one was similar to the first one, but residence (urban or rural) replaced wealth percentile in interaction. For each set, a second- and a third-degree polynomial for age were provided. Overall, the formula with second-degree polynomial on age and interaction between country and wealth percentile had the lowest cross-validation error of 23.59%.
3.2.5. Generalised Additive Model (GAM)
GAM allowed the age variable to be fitted with spline functions, potentially providing more flexibility. The basis was derived from the result of the best logistic regression formula. Basis cubic spline, cubic spline with one knot, and natural cubic spline with one knot were trained. Because in some surveys, the upper age is taken as 44 years,⁵ the knot was placed on 44. Cross-validation results showed that cubic spline with a knot on 44 had the lowest error rate of 23.57%, suggesting that placing the knot yielded improvement for the model.
3.2.6. Model Training Comparison
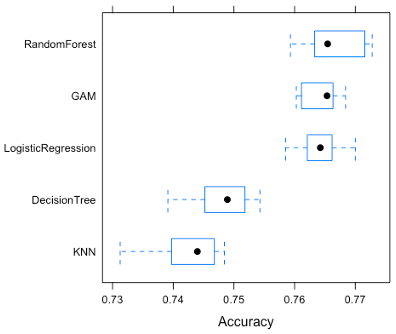
Figure 4 shows the distributions of 10-fold accuracy for five models. Random forest has the highest accuracy of 76.67%, followed by the 76.43% of GAM; 76.42% of logistic regression; 74.49% of decision tree; 74.23% of KNN. The GAM model has the smallest range, indicating consistency in predictive performance, however, given there are only ten folds, the distribution may not be representative. Surprisingly, in contrast to the initial strategy that non-parametric models would have better performance, KNN and decision tree did worse than parametric ones.
3.3. Model Testing
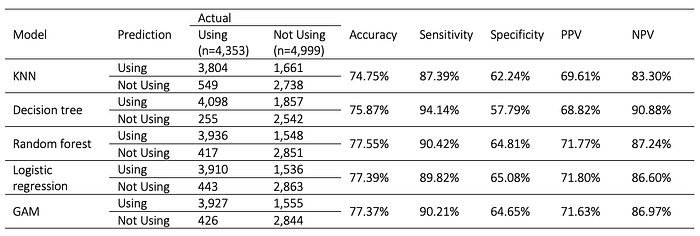
Using the validation set, which contains 8,752 observations, each model is tested with unseen data. Table 2 provided confusion matrices and performance measures. It can be seen that Type I Error (False Positive) occurs much more frequently than Type II Error (False Negative), suggesting that the models are generally better at identifying WRA currently using contraception than labelling those who are not.
Among the five models, random forest has the highest accuracy of 77.56%. Decision tree scores the highest in sensitivity and negative predictive value (NPV) at 94.14% and 90.88%, respectively. That is, when a WRA is using contraception, there is a 94.14% probability that decision tree will label her as using. And when an individual is predicted to be not using contraception by the decision tree, there is a 90.88% probability that she is not using any methods to avoid pregnancy. As for specificity and positive predictive value (PPV), the best performance is seen on logistic regression with Bayesian classifier with a specificity of 65.08% and a PPV of 71.80%. In this analysis, in which the goal is to classify women of reproductive age who are not using contraception, specificity is considered to be the most important performance metric, making logistic regression and Bayesian classifier the best model.
4. Conclusion
The study develops five classification models to predict the use of contraception in Thailand, Laos, and Mongolia using MICS microdata and machine learning techniques. Random forest model has the highest accuracy of 77.56 per cent and shows that marital status, country, and age are the most important predictors for contraception use. However, logistic regression with Bayesian classifier is selected to be the most fitted one for its ability to identify women of reproductive age who are not using contraception. When an individual is not using any methods to avoid pregnancy, there is a 65.08% of probability that logistic regression will correctly label the individual.
There are some limitations. Firstly, MICS is a cross-sectional survey that provides a snapshot of the population. Because some methods are reversible, such as intrauterine devices and contraceptive implants, MICS does not capture the patterns influencing an individual’s decision to change the adoption of contraception. Secondly, only a few variables from MICS are included in the analysis as described in Data Source and Process. As MICS data files contain more than one module, such as information on household characteristics, children’s health, and household members, merging WRA module with others will allow more variables to be analysed in this study. It is not done currently because UNICEF does not provide documentation on how to identify a unique individual across several modules.
Overall, while there are still many areas for improvement for the models, the study examined the determinants that influence the use of contraception and provided an example of how machine learning can be applied to the development sector.
Footnote
[1] The countries have different education systems and response categories. For example, Laos has “Post-Secondary” and Mongolia has “College”, and both are re-coded to “Higher”.
[2] In an ideal scenario with better computing power, I would try all integers from 1 to 9. However, even with just two mtry, it took nearly an hour to run.
Reference
¹ Kavanaugh, Megan L., and Ragnar M. Anderson. “Contraception and beyond: The health benefits of services provided at family planning centers.” (2013). https://www.guttmacher.org/sites/default/files/report_pdf/health-benefits.pdf
² United Nations, Department of Economic and Social Affairs, Population Division. “Contraceptive Use by Method 2019: Data Booklet (ST/ESA/SER. A/435).” (2019). https://digitallibrary.un.org/record/3849735?ln=en
³ Sedgh, Gilda, Lori S. Ashford, and Rubina Hussain. “Unmet need for contraception in developing countries: examining women’s reasons for not using a method.” New York: Guttmacher Institute 2 (2016): 2015–2016. https://www.guttmacher.org/report/unmet-need-for-contraception-in-developing-countries
⁴ Kotsiantis, Sotiris B., I. Zaharakis, and P. Pintelas. “Supervised machine learning: A review of classification techniques.” Emerging artificial intelligence applications in computer engineering 160.1 (2007): 3–24.
⁵ World Health Organization. (2006). Reproductive health indicators : guidelines for their generation, interpretation and analysis for global monitoring. https://apps.who.int/iris/handle/10665/43185
This paper was finished on 30 November 2020 by Yu-En Hsu with the guidance from Dr Lopoo.
